
Starter Social Media OSINT

OSINT, or Open-source Intelligence, are a set of techniques for data collection and analysis that is publicly available from various sources on the web (and beyond) in order to gain an understanding about a target, environment, business or thing.
If you have ever tried to Google someone's information, reviewed what people have had to say about a business, or simply tried to piece together a story with the information you received, you began engaging in what's known as "passive reconnaissance". By nature, humans are curious and might perform a variety of searches for different reasons (these can be anything from safety concerns to checking to see if someone is a scammer etc...).
The term itself was coined through techniques used by the NSA, law enforcement officials, and various analysts who used this information to varying degrees
Publicly available data is everywhere. Everything from breached accounts, to social media sites, blogs and news outlets and even publicly available government data exists everywhere. As time goes on and the Internet advances, there is little to no information that can't be found about a lot of people, so it's important to understand how what we say and do online provides a roadmap to our lives.
Social Media

Social media has a huge presence in most of our lives and is everywhere, so being able to glean information from various profiles is often a first go-to for doing research. It's important to know how to utilize tools, websites and the platforms themselves in order to help you find more information about the accounts you wish to do research on.
Here is a list of some top social media platforms and while there are quite a few others, I didn't want to write about every social media platform, so I left them off the list:
Keep in mind there are a lot of other sources where people might list their information publicly. Here are a few I never see mentioned (but may be found on timelines):
It's important to note OSINT resources for Social Media constantly change over time, so what works now may not in the future. It's important to keep tabs on various tools and engines as results change.
While these tools are incredibly interesting, they can create false-positives, so be sure to be thorough when checking through results.
ALSO NOTE: Using or writing scraping tools can also be relatively volatile in the same manner, because companies would prefer you use their API and tend to get annoyed when people don't. ;)
1. Facebook

With roughly 36.9% of people on the planet using Facebook, it's not only the largest and most well-known social media sites that still exist, but it has over 2 billion active users monthly.
- Most people are familiar with Google, but adding a few operators like site:, inurl:, or name +Facebook can expand and broaden your search.
Just viewing someone's page can tell you a lot about them. Listed in the image below, we see users have the ability to post a LOT of personal information about themselves or their company. Every one of these items could be useful to help gather information.
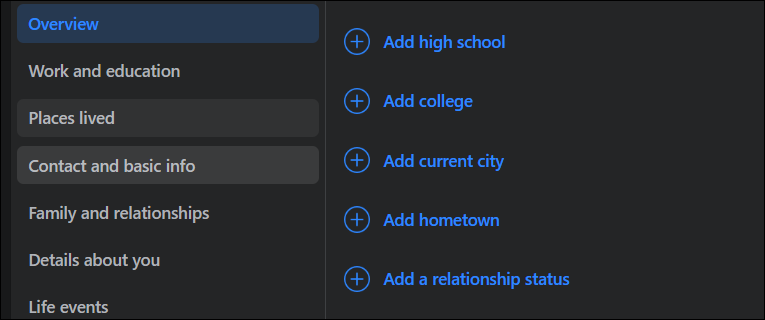
Look at friends, reviews, groups and the kinds of posts typically made. All of these could be useful.
- As of writing this Lookup-ID still works and allows you to quickly grab a FID (Facebook ID), which is the number associated with an account. It's good to know the FID because while usernames change, the FID doesn't.
- Facebook ID's can also be found manually, by hitting ctrl +U, then ctrl +F and searching for profile_id, or entity_id in the page source. The ID will be the numbers listed in quotes. You can verify an ID by going to https://www.facebook.com/FID
- Identifiers like the ones listed above are: page_id, and group_id
- Facebook requests start like this: facebook.com/search/top/?q=people&epa=FILTERS&filters= to which you can use the table below to help guide you.
| top/ | search top content |
| posts/ | search top posts |
| people/ | search for people |
| videos/ | search for videos |
| pages/ | search for pages |
| places/ | search for places |
- If you're looking for the more detailed version of this which includes how to use JSON and base64 to apply filters, Kirby Plessas runs an ongoing page called facebookmatrix that deserves good mention and goes into this in more depth. The page is also updated as changes to structure and queries do.
- Some more direct resources: whopostedwhat, sowsearch, one-plus, and intelx
- Lastly, did you know there's a tool that monitors FB statuses in order to measure sleep patterns through user activity? If not, check it out:
 sqren
sqrenThere are a lot of tools and websites that exist, but definitely check out the OSINT framework site if you're looking for added resources: OSINT Framework
Before continuing to other platforms, I want to quickly mention cross-platform searching to connect various social media accounts. There are a few websites and tools that exist, but here are the ones I prefer.

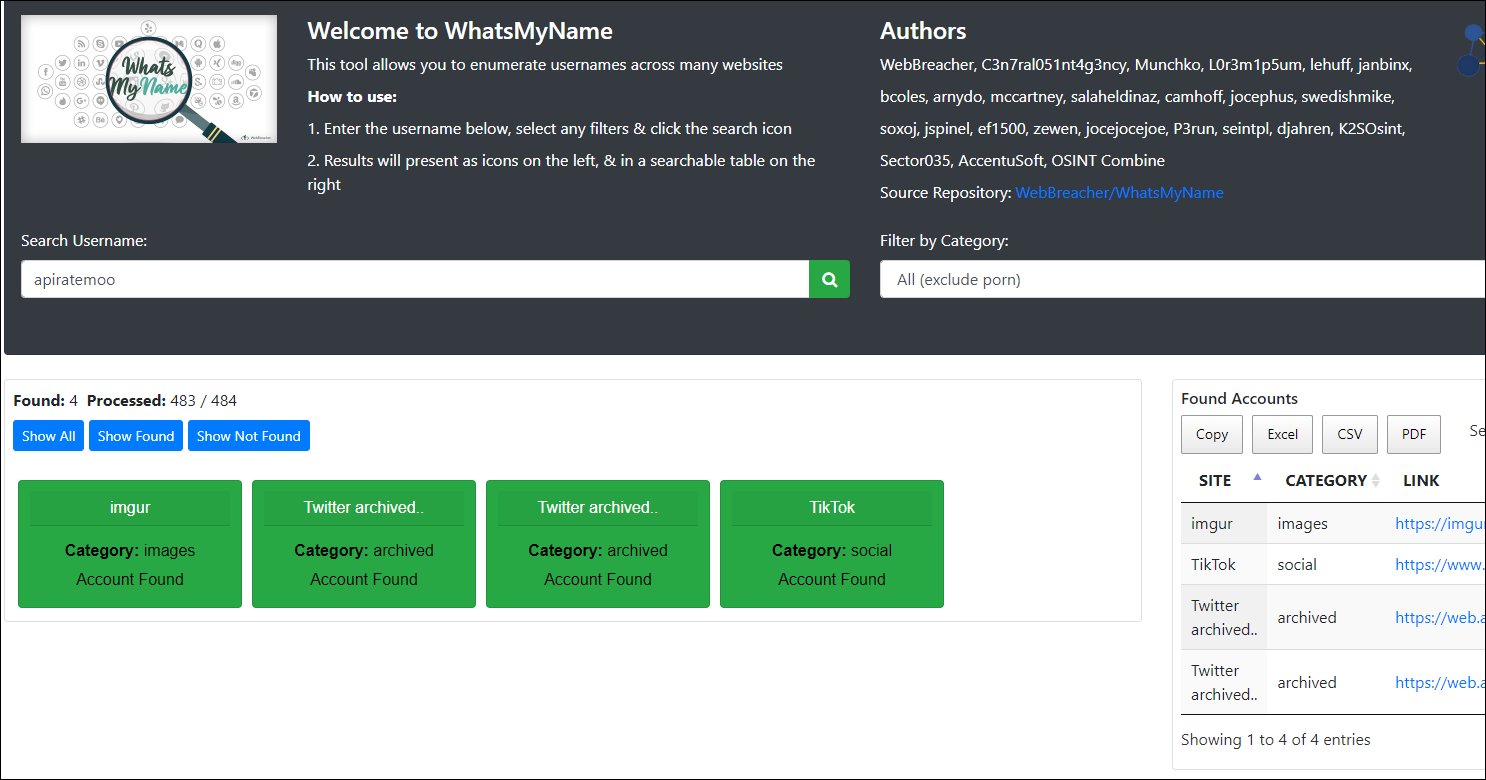
WhatsMyName
A cross platform searching tool that quickly checks a username, which can then be exported into file formats for archiving. In the image below, you can see an example search of yours truly.
Sherlock
Sherlock is a python based tool that searches over 300 social media platforms. Below I provided the same search in Sherlock and you can see the results are a bit better then WhatsMyName's.
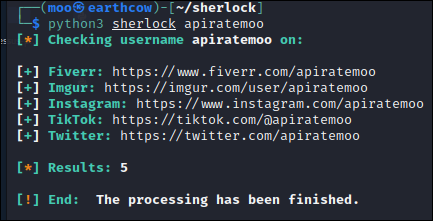 sherlock-project
sherlock-project2. YouTube
There are a few cool resources for people looking to pull information from YouTube:
- YouTube Metadata Grabs details about a video/playlist/creator/channel
- YouTube Geofind Checks uploads for geotagged videos/provides a map
- WatchFramebyFrame Allows you to mess with video frames
Tools like jq, curl, and bash can pull some interesting info off social media, but you can also hit F12, go to Network, refresh the page and check the XHR tab and see if any interesting information is going out.
If you're not familiar with jq, I should mention it can be a pain. For the brave and curious: https://cameronnokes.com/blog/jq-cheatsheet/
3. Twitter
Twitter advanced search is a great tool provided by the company which allows for a lot of deep dive searches into various tweets. You'll be prompted with a lot to choose from ranging from phrases, words, or hashtags which you can use to monitor posts.
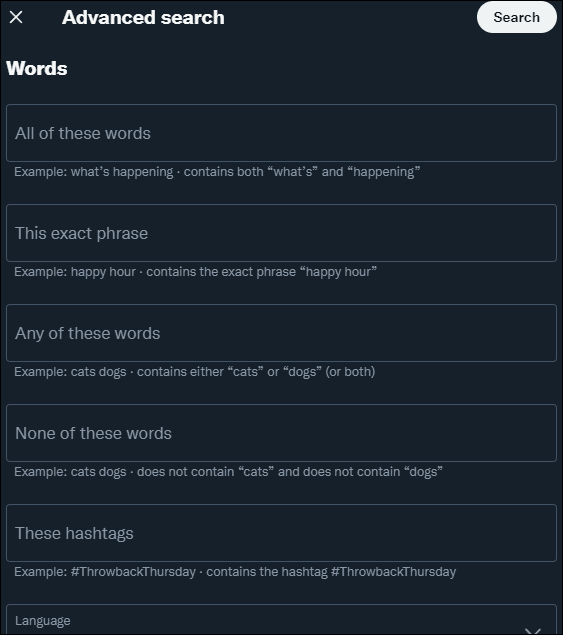
Twitter also has a lot of queries that can be used to gain more specific information about various thing. You can use from:username to find all tweets sent by that user and can filter:replies, or exclude:replies when searching through the site.
Other interesting queries: filter:retweets, and exclude:retweets (only show/exclude retweets), keyword filter:news (gain access to news), filter:images, and from:mary to:sarah (this would grab tweets from mary that mention sarah)
- Like FB, Twitter has its own ID and you can go to TweeterID to find an ID quickly. Tweetdeck is nice in the sense that you can modify the board to how you want things to be displayed and view multiple things at once. While OneMillionTweetMap is neat in the sense that it uses a live map to track tweets as they're going out, I don't see it as being a very practical tool.
- Socialbearing, Spoonbill and foller.me are pretty decent for info. I did look into twint and really, really, wanted this to work, but I couldn't get it working for whatever reason.
- Tinfoleak lists and emails a bunch of profile information about a user as seen in my example below:
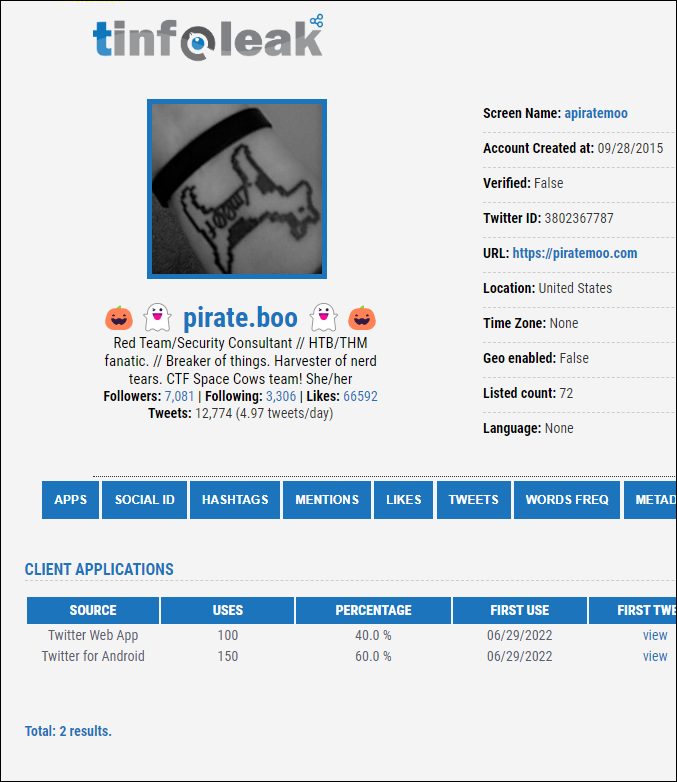
4. Reddit
Reddit is a place often overlooked, that can supply a wealth of info about users. The URL for usernames is: https://www.reddit.com/user/username and to look at a user's posts, simply append /posts/ to the above link. If you would like to see the user's comments, simply append /comments/ to the end of the URL above.
- In the link below, you can see a sample of what a Reddit profile looks like, how much karma an individual has and their cake day (anniversary).
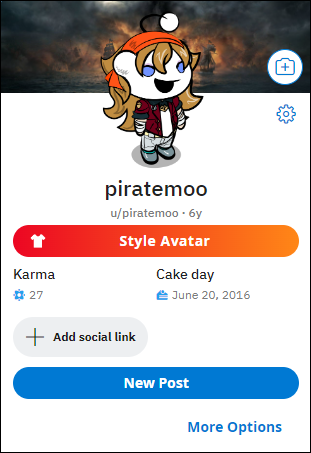
- Since removeedit no longer exists to look at deleted and removed posts and comments, unddit has sort of taken its place
5. LinkedIn
LinkedIn is always a great resource for discovering information about users and businesses, but pulling information does require you to have a sock puppet of some kind. This is because both free and premium members can view the individuals who looked at their profile.
- URLs follow an easy URL scheme: https://linkedin.com/in/ with the person, company name, job title or keyword appended to the link. If you want to grab the profile photo, then you can just append /detail/photo.
- There is a lot of documentation about creating sock puppets, and a lot of it retains common sense information like (actually have an account with content that isn't a week old), so I'm not really going to go in-depth with it here
You can save profile information in a PDF style format as well:
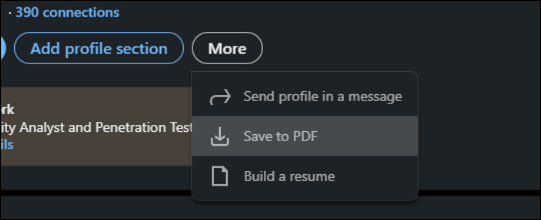
Images
Sometimes it's a good idea to cross reference images found on the web in order to gain more information. This can come in the form of Most of us are familiar with reverse image searches with engines like Google, so I won't really delve into that much, other than tossing some links for reference.

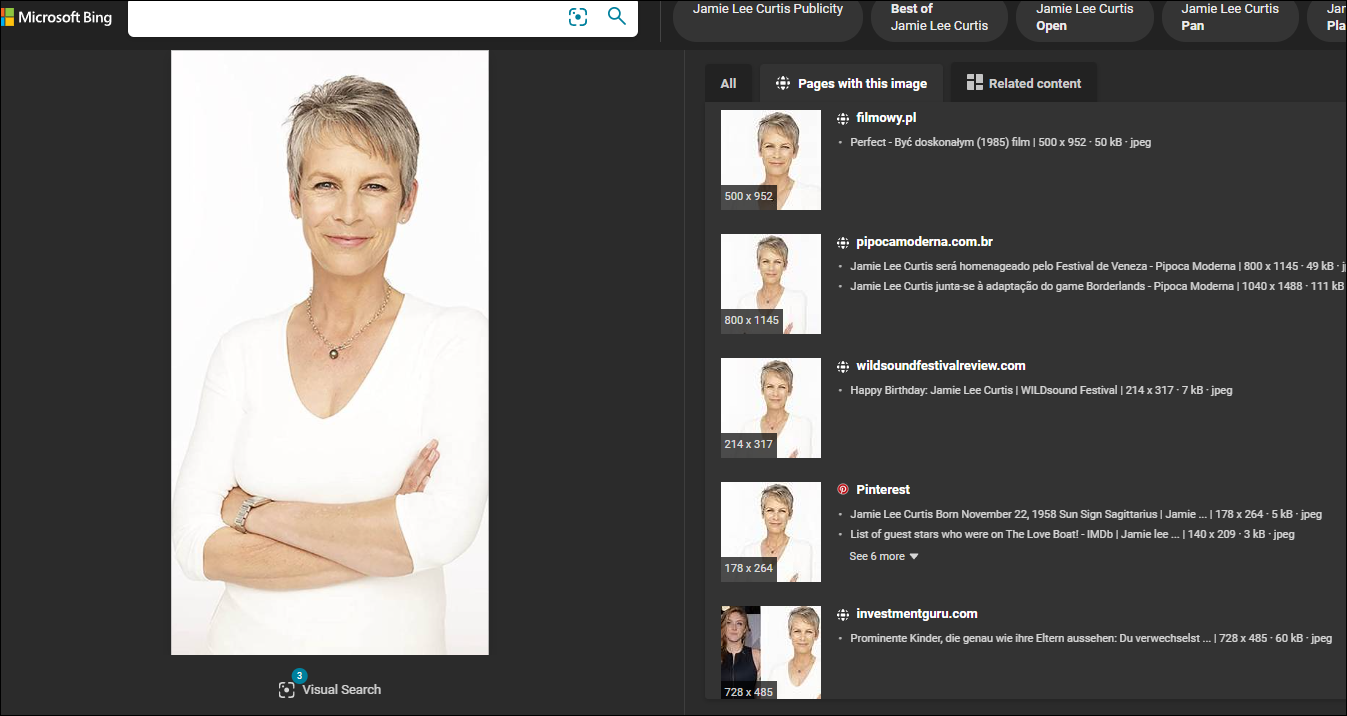
Uploading a picture of Jamie Lee Curtis for example, will yield some good results with Google's reverse image search:
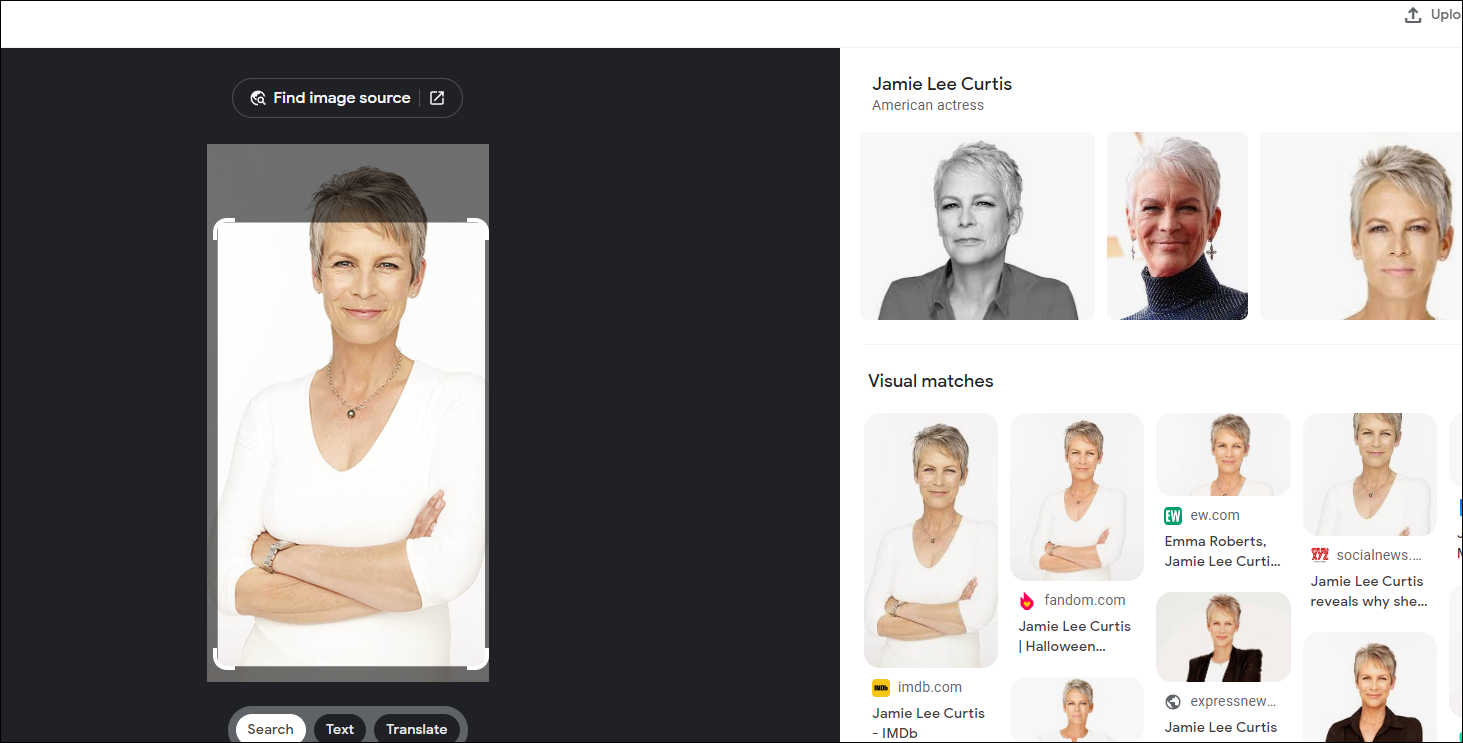
If you're mobile you can also try Google Lens:

Other engines like Bing's Image search are also nice at times, primarily because of the "Pages with this image" tab.
Metadata (meaning "data within data") and more specifically EXIF (Exchangeable Image File Format) can yield a little bit of a timeline and some information about where an image was taken, what device it was taken on, coordinates and the time/date the image was created.
- There are online viewers like exif.tools and Aperisolve you can use to extract information from images online and they happen to be very handy for CTF's as well.
Aperisolve
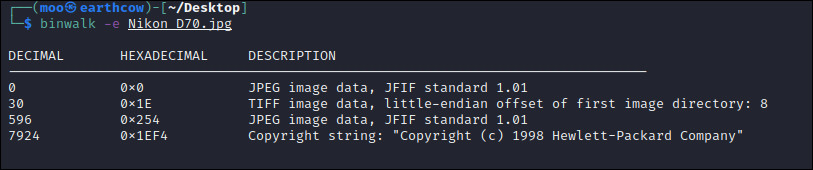
My general go-to tool because it performs all kinds of image analysis quickly that I usually run in Linux anyway, as seen in the image (exiftool ,binwalk, strings):
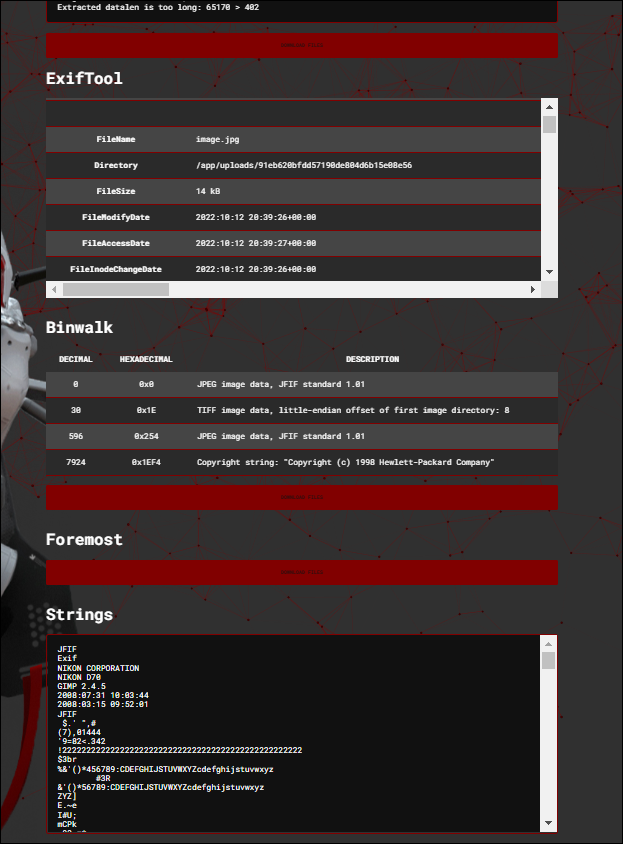
As you can see, running exiftool and binwalk on the image in yields the same results:
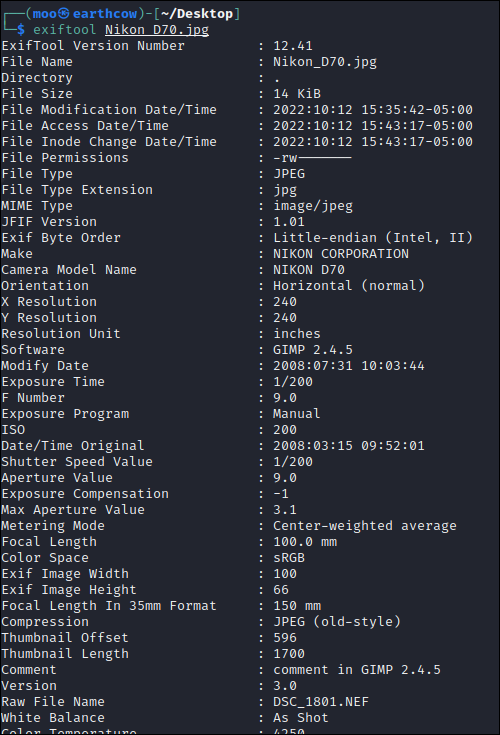
Dorking
Most of us are familiar with Google dorking (or using specific operators in order to yield better and more specific results from your searches), and there are entire blogs devoted to it, so I won't dive too deep, just list a few of my quick favorites:
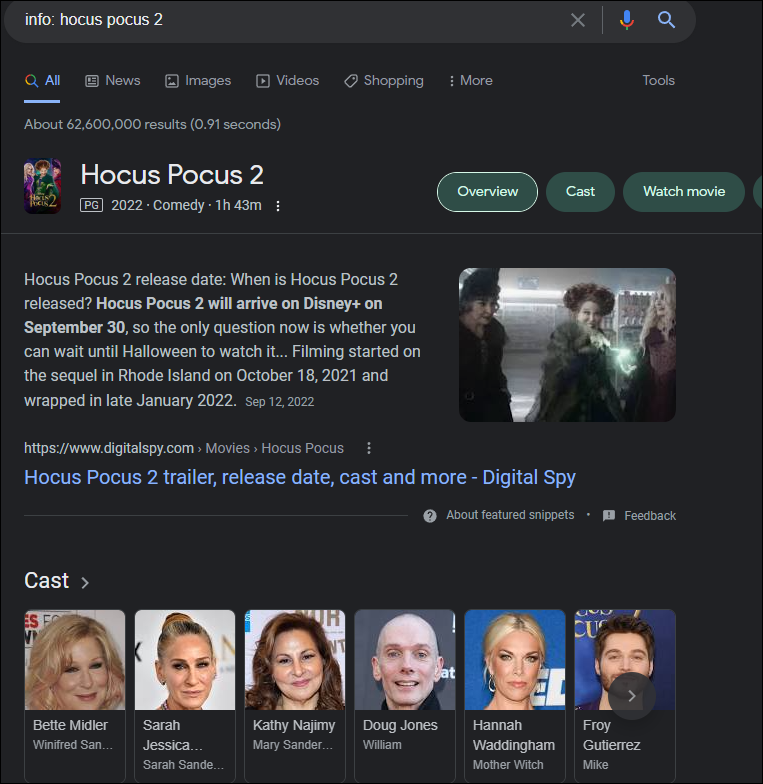
- info: (lists information about a topic), and define: (provides a definition)
- A few other quick and easy dorks are: site:, intitle:, inurl:, +, OR, - , filetype:
- If you're looking for more information about Google dorking check this article out: https://medium.com/infosec/exploring-google-hacking-techniques-using-google-dork-6df5d79796cf
- The GHDB (Google Hacking Database) currently has over 3,300 different sets of dorks that can be played around with. You can find it here:

- If you're just really bad at dorking and want an easy way out, try Google's advanced search instead (which will do some of the dorks for you): https://www.google.com/advanced_search
While there are a ton of other different OSINT techniques and tricks that can be performed (especially in a larger sense, regarding emails, leaks and a number of other things), these should help you out with the basics until you get a little more research in.
Happy Hacking :)